Introduction
GraphQL is a query language for APIs, providing a flexible and efficient alternative to REST. It was developed by Facebook in 2012 and open-sourced in 2015. Since then, it has gained immense popularity due to its ability to optimize data retrieval and offer greater control over the responses. In this blog post, we’ll learn the basics of GraphQL, its pros and cons, and then come up an example written in Go: we’ll go through schema design, code generation from schema with genql, and implementation of resolver functions.
Why use GraphQL
Behind the scene GraphQL uses the same network protocol as REST, however, there are a couple of advantages that GraphQL brings about:
- Efficient Data Fetching: a GraphQL client can specify exactly what fields they need in an API response, thus reducing the network bandwidth needed to carry out the operation. While this can be done with REST as well, it can be awkward to set up especially when there are too many nested fields under a complicated structure
- Single end-point: Unlike REST, by convention GraphQL provides a single end-point to handle all its query and mutation operations, removing the design overhead that’s common with REST (e.g. which path and which REST method to use)
- Strict Typing: GraphQL usually comes with a schema with strict types, making it clearer for clients to consume the API. Meanwhile REST usually comes with a JSON schema, which supports a much looser type system, and thus often accompanied with a document that depicts the contract between client and server.
- Self-documenting: Because of the nature of its strict typing relfected in the graph schema, GraphQL is self-documenting, allow client to introspect data types and operations.
However, GraphQL does come with its own list of disadvantages:
- Increased complexity: The flexibility of GraphQL can sometimes introduce complexity, especially when building deeply nested queries.
- Caching challenge: While REST lends itself to traditional HTTP caching, GraphQL does not benefit from the same method, and thus requires additional caching strategies in systems that require scalability.
Example
We will provide an example to illustrate how GraphQL works in Go. We utilize glqgen to generate data types and resolvers for our server. At the time of writing, the latest version of glqgen is v0.17.55.
In our example, we’ll create an application that allows fetching product data, along with their associated reviews, and adding new reviews for an existing product. To begin implementing the server, navigate to our server project directory and initialize it with glqgen
cd path/to/our/project
go run github.com/99designs/gqlgen init
This will produce the following layout in our project directory
├── go.mod
├── go.sum
├── gqlgen.yml - gqlgen config file
├── graph
│ ├── generated - A package that only contains the generated runtime
│ │ └── generated.go
│ ├── model - A package for all our graph models
│ │ └── models_gen.go
│ ├── resolver.go - The root graph resolver type (not regenerated)
│ ├── schema.graphqls - Our graph schema file, can be splitted
│ └── schema.resolvers.go - the resolver implementation for schema.graphql
└── server.go - The entry point to our app
Next, we overwrite graph/schema.graphqls with the following content
type Product {
id: ID!
name: String!
reviews: [Review]
}
type Review {
id: ID!
content: String!
rating: Int!
productId: ID!
}
type Query {
getProduct(id: ID!): Product
}
type Mutation {
addReview(productId: ID!, content: String!, rating: Int!): Review
}
This schema defines Product and Review types with a one-to-many relationship, a query to get product by ID, and a mutation to add review to an existing product. Now run go run github.com/99designs/gqlgen generate to generate the models and boilerplate resolvers for our GraphQL server. After code generation, it can be noticed that our models will be generated in graph/model/models_gen.go, our server execution code in graph/generated.go and schema resolver under schema.resolvers.go with the resolver struct defined in graph/resolver.go. The generated models and server execution code don’t require modification, but we need to update our schema resolver.
In this example, we’re storing products data in application memory. We update resolver.go by adding products []model.Product as a property of Resolver, and allowing injecting a list of products in NewResolver
type Resolver struct {
products []model.Product
}
func NewResolver(products []model.Product) *Resolver {
return &Resolver{products: products}
}
Now we can switch to server.go to update our graph server with some initial products
srv := handler.NewDefaultServer(
graph.NewExecutableSchema(
graph.Config{Resolvers: graph.NewResolver([]model.Product{
{
ID: "1",
Name: "macbook pro 2023",
Reviews: []*model.Review{
{
ID: "1",
Content: "very good laptop",
Rating: 10,
ProductID: "1",
},
{
ID: "2",
Content: "nice to have",
Rating: 9,
ProductID: "1",
},
},
},
{
ID: "2",
Name: "macbook air 2023",
Reviews: []*model.Review{
{
ID: "1",
Content: "battery could be better",
Rating: 7,
ProductID: "2",
},
{
ID: "2",
Content: "should have bought the pro version",
Rating: 5,
ProductID: "2",
},
},
},
})},
),
)
The last thing we need to do to finish the server code is to update schema.resolvers.go. We update method GetProduct first, simply looking up the product ID in the list of products as a property of the resolver
func (r *queryResolver) GetProduct(ctx context.Context, id string) (*model.Product, error) {
for _, p := range r.products {
if p.ID == id {
return &p, nil
}
}
return nil, fmt.Errorf("cannot find product with id %s", id)
}
Next, we update AddReview method as following
func (r *mutationResolver) AddReview(ctx context.Context, productID string, content string, rating int) (*model.Review, error) {
idx := -1
for i, p := range r.products {
if p.ID == productID {
idx = i
break
}
}
if idx == -1 {
return nil, fmt.Errorf("cannot find product with id %s", productID)
}
return addReview(&r.products[idx], content, rating)
}
func addReview(p *model.Product, content string, rating int) (*model.Review, error) {
r := &model.Review{
Content: content,
Rating: rating,
ProductID: p.ID,
}
p.Reviews = append(p.Reviews, r)
return r, nil
}
Our server is now ready to serve products data. gqlgen also provides a playground environment where we can interact with the server. Start by running go run ., and then access the playground at http://localhost:8080.
We can issue the following query to fetch data of product ID 1
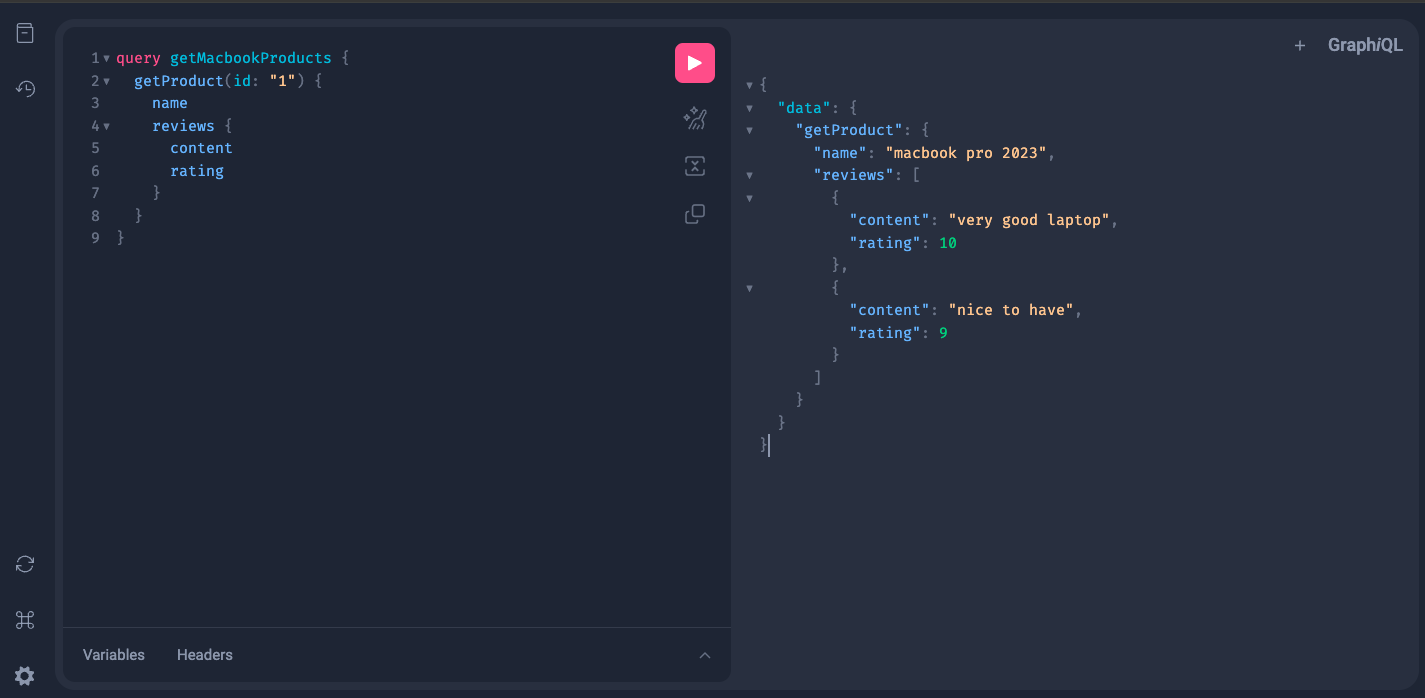
We can also use HTTP to run the query, as shown in the following client example
package main
import (
"bytes"
"encoding/json"
"fmt"
"log"
"net/http"
)
type ProductQuery struct {
Query string `json:"query"`
Variables struct {
ID string `json:"id"`
} `json:"variables"`
}
func main() {
client := &http.Client{}
query := ProductQuery{
Query: `query getProduct($id: ID!) {
getProduct(id: $id) {
id
name
reviews {
content
rating
}
}
}`,
}
query.Variables.ID = "1"
jsonData, err := json.Marshal(query)
if err != nil {
log.Fatal(err)
}
req, err := http.NewRequest("POST", "http://localhost:8080/query", bytes.NewBuffer(jsonData))
if err != nil {
log.Fatal(err)
}
req.Header.Set("Content-Type", "application/json")
resp, err := client.Do(req)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
var result map[string]interface{}
json.NewDecoder(resp.Body).Decode(&result)
fmt.Printf("Response: %+v\n", result)
}
In playground, we can also run a mutation like this:
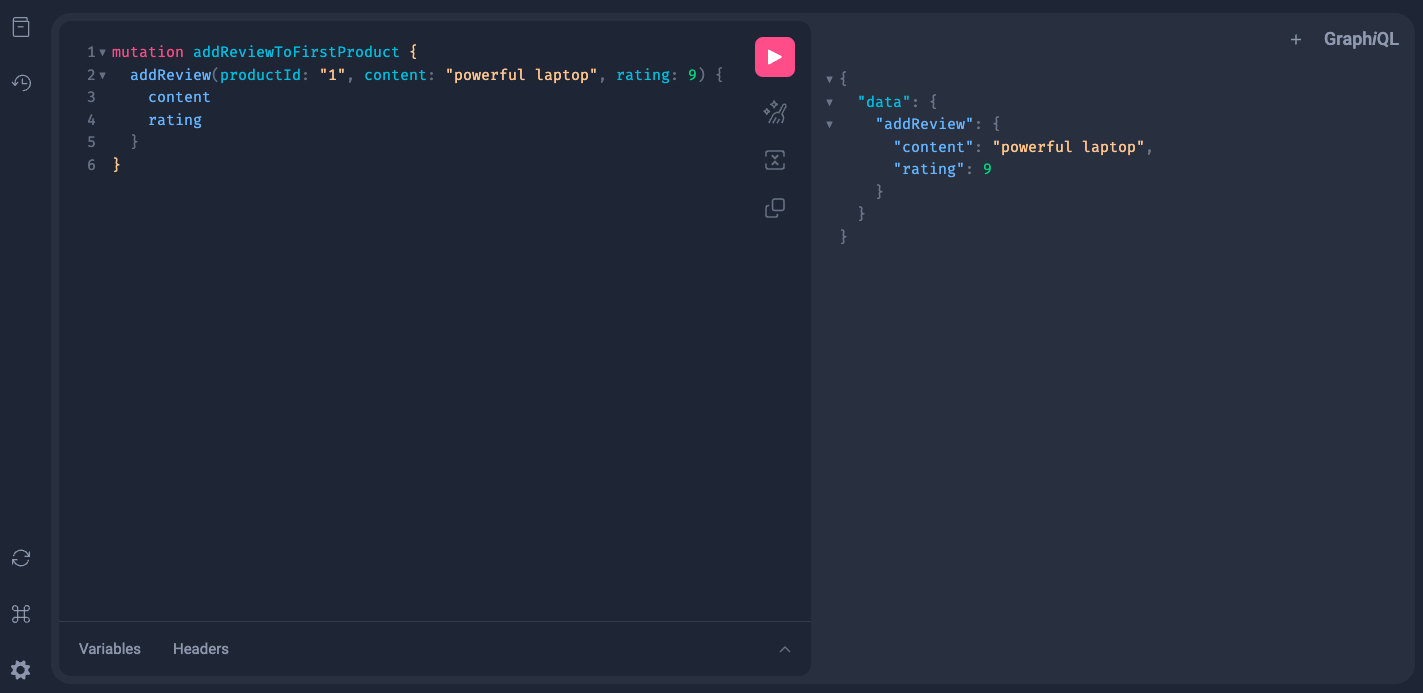
Summary
In this blog post, we explored how to write a basic GraphQL server, run queries and mutations in playground environment provided by gqlgen. In the next post, we will delve into advanced topics in GraphQL such as federation and data loaders.